My new R package regrake is now live!
Regularized raking enables more flexible functional forms in raking to population targets, leading to more expressive and efficient survey weights.
You can install the package from r-universe or github:
install.packages("regrake", repos = "https://andytimm.r-universe.dev")The rest of this post gives a light overview of the problem regularized raking solves, and introduces some interface elements I’m excited by.
Flexible raking and regularization
Survey researchers increasingly ask a lot of our weights. We know our sample can be subtly or not so subtly unrepresentative in hard to fix ways, and expansive weighting schemes, no matter how imperfect, are part of the toolkit to address these challenges. Take, for example, the growing list of weighting variables in any recent NYT survey1.
What does this have to do with how exactly we fit our weights, though?
I find an analogy to predictive modeling instructive here. The early calibration literature like Deville & Särndal (1992) makes it pretty clear that raking can be roughly understood as linear regression on the weighting problem2. Like with linear regression in the predictive context, we can add more marginal terms and interactions to (perhaps) fit a better model. Layering in more and more predictors like this allow one to extract further signal from your data, but you’ll quickly begin to feel the inflexibility of a simple regression framework as problems get more complex.
Pushing all the way to a highly flexible, probably Bayesian or machine learning model to pull more signal out of available data without a variance explosion works, but often a simple lasso, ridge, or horseshoe prior regression model provides most of the additional signal for minimal additional effort. I think the regularized raking available in regrake offers a compelling level of flexibility without much more implementation complexity.
Here’s an example: In the 2016 pew study I’m weighting in the slides below, we should have some intuition that getting Trump vote choice right is relevantly about not just marginal distributions of weighting dimensions like age, gender, race, region, and education, but also many interactions between these — whomst amongst us hasn’t worried about non-college midwestern whites? However, a more fully interacted model won’t3 converge with basic raking, and the nearby partial solutions pay a relatively large variance cost4.
A sensible path forward available with regularized raking is to still require exact matching on all the marginal distributions, but optimize for merely least squares close target adherence on relevant 2 and 3-way interactions. When combined with some relatively light touch regularization, we end up with pretty clean target adherence.
The plot below shows deviation from population targets across all the constraints using regrake — finding a solution within about 1 percentage point on the harder interaction terms allows us to fit something more expressive:
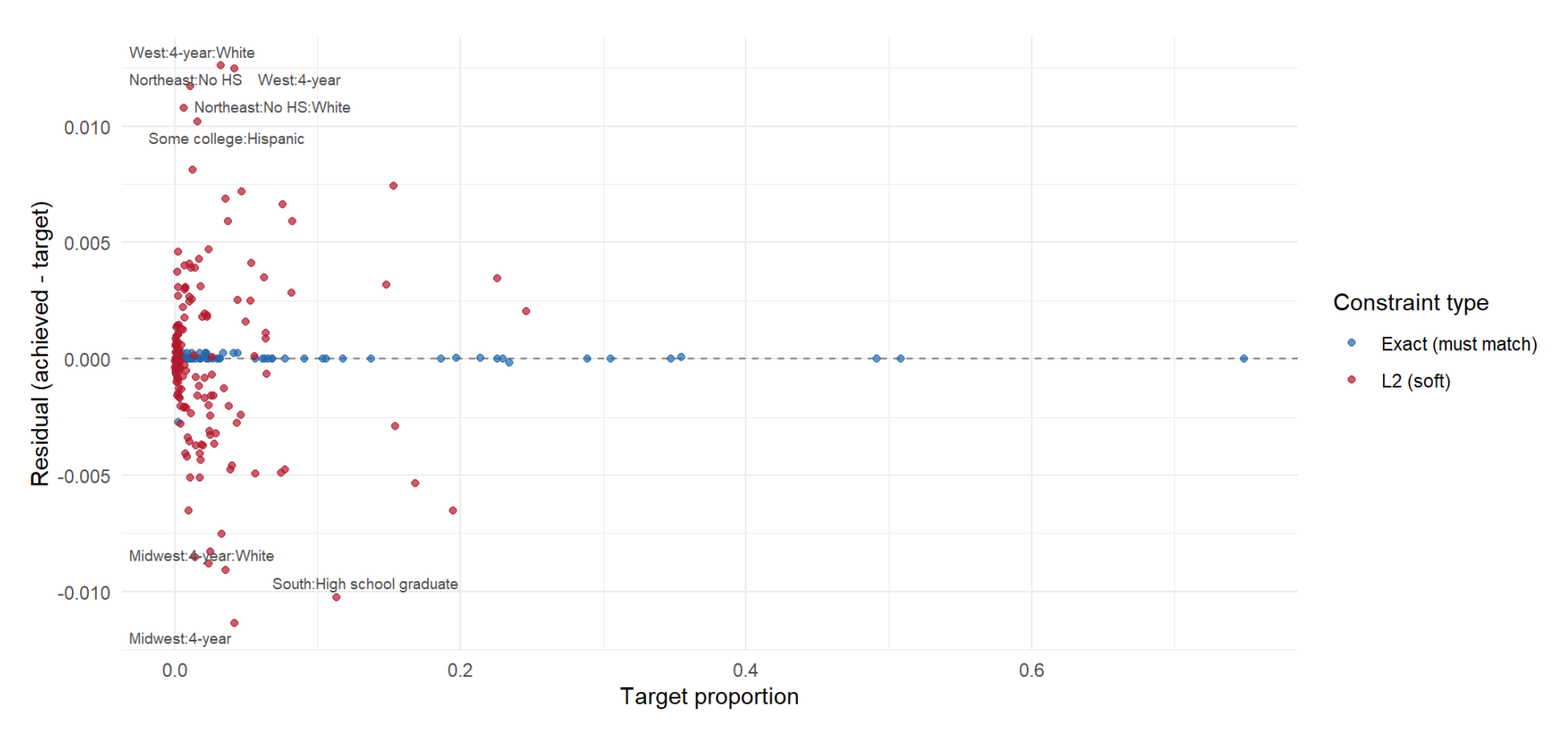
While there are certainly applications that call for going all the way to something more complex like MRP, my sense is regularized raking can deliver much of the incremental benefit at lower effort. Coming back to that predictive modeling analogy, the sample you start with and the variables you choose to weight on still matter more than anything about how you weight, but more expressive tools give you better action space.
Formula interface
I’ve always been inspired by the elegance of brms’s formula interface: Even complex models feel pretty easy to express elegantly. I’ve tried to capture some of that experience here.
regrake makes it pretty easy to specify relatively complex constraints, like a mix of exact constraints on marginal totals and L2 constraints on interactions:
regrake(
data = survey_data,
formula = ~ rr_exact(recode_age_bucket + recode_female +
recode_inputstate + recode_region +
recode_educ + recode_race) +
rr_l2(recode_region:recode_educ +
recode_region:recode_race +
recode_educ:recode_race +
recode_region:recode_educ:recode_race),
population_data = pop_targets,
pop_type = "proportions",
regularizer = "entropy",
lambda = 10
)Swapping a constraint from rr_exact() to rr_l2(), or tweaking lambda to adjust regularization, is a one-line change, which makes it easy to iterate and compare.
Target Input Interfaces That Don’t Suck
Structuring weighting target inputs in R has always been moderately annoying to me. One thing I’m happy with here is that I’ve been able to support a pretty wide set of input formats.
For example, I find the autumn df format pretty elegant:
targets <- tibble(
variable = c("sex", "sex", "age", "age",
"sex:age", "sex:age", "sex:age", "sex:age"),
level = c("M", "F", "young", "old",
"M:young", "M:old", "F:young", "F:old"),
target = c(0.49, 0.51, 0.45, 0.55,
0.20, 0.29, 0.25, 0.26)
)
targets# A tibble: 8 × 3
variable level target
<chr> <chr> <dbl>
1 sex M 0.49
2 sex F 0.51
3 age young 0.45
4 age old 0.55
5 sex:age M:young 0.20
6 sex:age M:old 0.29
7 sex:age F:young 0.25
8 sex:age F:old 0.26But the package is just as happy to take an anesrake style list:
targets <- list(
sex = c(M = 0.49, F = 0.51),
age = c(young = 0.45, old = 0.55),
`sex:age` = c(`M:young` = 0.20, `M:old` = 0.29,
`F:young` = 0.25, `F:old` = 0.26)
)
targets$sex
M F
0.49 0.51
$age
young old
0.45 0.55
$`sex:age`
M:young M:old F:young F:old
0.20 0.29 0.25 0.26Or a poststratification table:
pop_table <- tribble(
~sex, ~age, ~count,
"M", "young", 2000,
"M", "old", 2900,
"F", "young", 2500,
"F", "old", 2600
)
pop_table# A tibble: 4 × 3
sex age count
<chr> <chr> <dbl>
1 M young 2000
2 M old 2900
3 F young 2500
4 F old 2600These are ultimately all converted back to the autumn format for use. My hope is that this fluidity with inputs makes it a bit easier to try regularized raking on your data.
Learning More + Contributing
If this has piqued your interest, a good longer introduction to regularized raking is these slides, a slightly updated version of a talk I gave at NYOSPM.
If the underlying optimization logic is interesting to you, I’d check out Barratt, Angeris, and Boyd (2021)- it’s a really clean, elegant application of alternating direction method of multipliers (ADMM) ideas and super readable.
Of course, this is a 1.0 release, so there are bound to be minor issues floating around. If you run into any issues or have an idea to expand the functionality, I’d welcome issues on GitHub.
Footnotes
Check out this long list of weighting variables- many of which my mentors from an earlier era of polling would find anathema to weight on!
 Source: NYT/Siena National Poll Toplines, January 2026↩︎
Source: NYT/Siena National Poll Toplines, January 2026↩︎I’m being a little loose here in service of keeping the post going. If you take away “raking has linear regression vibes”, and “regularized regression has lasso/ridge/horseshoe vibes” I’m happy. More precisely, Deville & Särndal show that all calibration estimators, raking included, produce point estimates asymptotically equivalent to the generalized regression (GREG) estimator, which adjusts the Horvitz-Thompson estimator via a linear regression on the calibration margins. So raking on age and sex separately implicitly fits a main-effects-only linear model; no interactions. The weights themselves differ across calibration distance functions (raking guarantees positivity, for instance), but the estimates converge IIRC.↩︎
For anybody else who reads “won’t” as a challenge here, I’m aware of the various tricks one can resort to here. Picking and choosing interactions to keep, raking in stages, or being flexible with what “converged” needs to mean…. all these could probably get something close to the example to fit. The example is (deliberately) just simple enough that vanilla raking starts to struggle- you could force it to work. My claim here is that you shouldn’t have to resort to these sometimes hacky tricks we’ve collectively figured out: instead, try to formalize the solution you actually want, and optimize against that.↩︎
Similar to the above footnote, if your reaction here is that you’ve got plenty heuristic tools like trimming or winsorization to bring down that variance/deff cost, again my claim is that you shouldn’t have to do this. Instead, you can write down the optimization problem you actually want to solve, weighting induced variance limitations included, and directly solve that.↩︎
Reuse
Citation
@online{timm2026,
author = {Timm, Andy},
title = {Regrake: {Regularized} {Raking} in {R}},
date = {2026-02-22},
url = {https://andytimm.github.io/posts/announcing_regrake/announcing_regrake.html},
langid = {en}
}